|
I am a doctoral student at the School of Software, Tsinghua University, advised by Prof. Yu-Shen Liu. During my studies, I majorly conduct 3D computer vision research. Specifically, my research interests include 3D reconstruction, multi-view 3D reconstruction, and surface reconstruction from point clouds. I enrolled in 2019 and expected to graduate in June 2024 with a Ph.D. I am looking for job opportunities related to 3D computer vision. If there are cooperation opportunities, please contact me by email. |

|
|
I'm interested in 3D computer vision, deep learning, optimization. Much of my research is about single view 3D recontruction from point clouds, 3D implicit surface reconstruction. Representative papers are highlighted. |
|
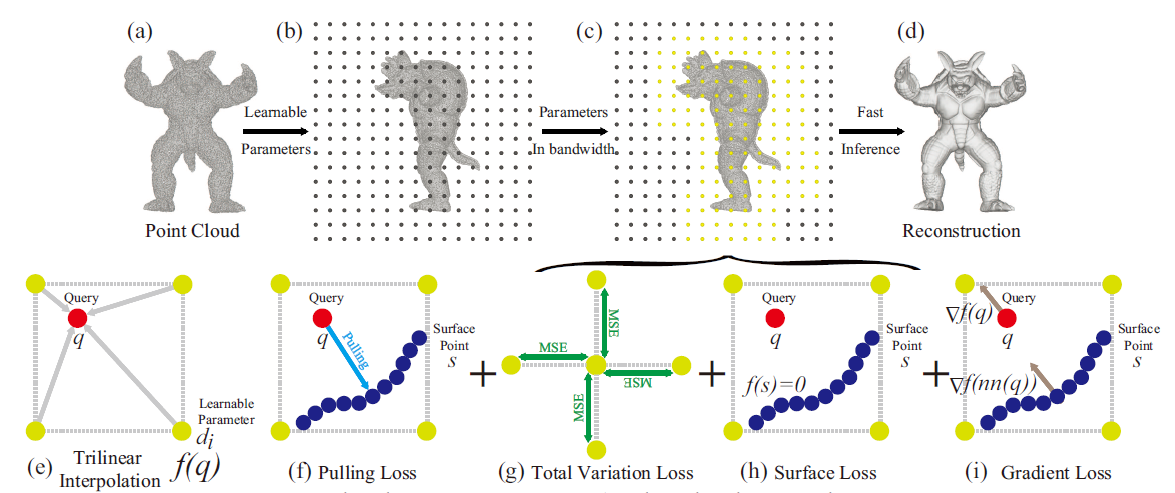
Chao Chen, Yu-Shen Liu*, Zhizhong Han, Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023 We propose GridPull to reconstruct surface fastly from large scale point clouds without using neural networks. |
|
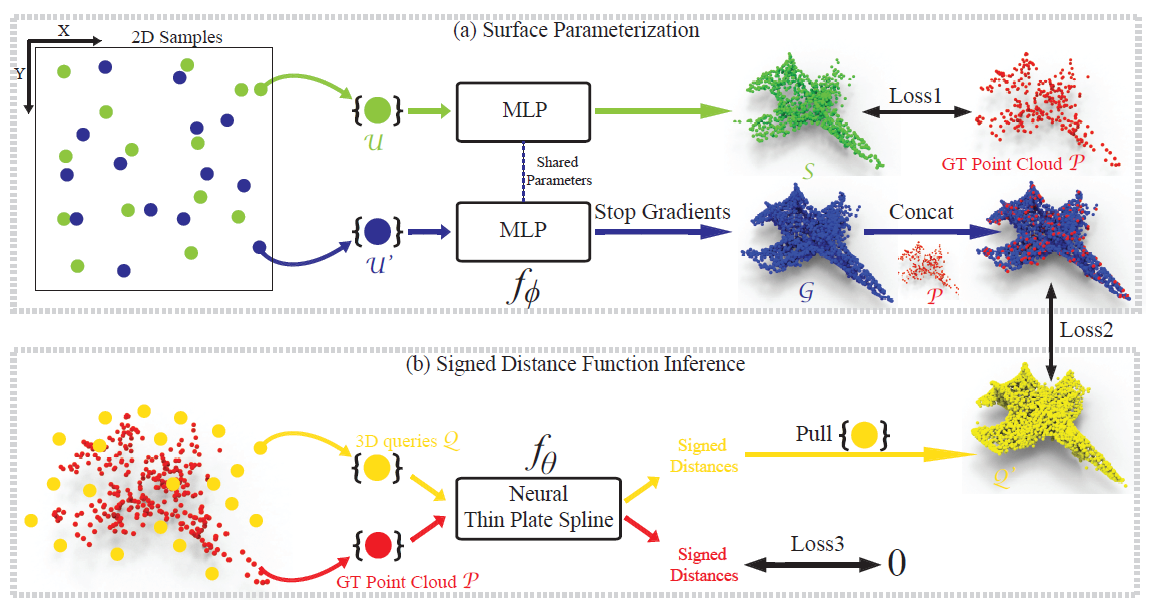
Chao Chen, Yu-Shen Liu*, Zhizhong Han, Proceedings of the IEEE/CVF Conference on Computer Vsion and Pattern Recognition (CVPR),, 2023 github / open access / arXiv We introduce a neural network to infer SDFs from single sparse point clouds without using signed distance supervision, learned priors or even normals. |

|
Chao Chen, Yu-Shen Liu*, Zhizhong Han, European Conference on Computer Vision (ECCV), 2022 project page / arXiv We introduce a novel implicit representation to represent a single 3D shape as a set of parts in the latent space, towards both highly accurate and plausibly interpretable shape modeling. |

|
Chao Chen, Yu-Shen Liu*, Zhizhong Han, Matthias Zwicker, Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021 github / open access / arXiv / media report We introduce a method to enable the unsupervised learning of 3D point cloud generation with fine structures by 2D projection matching. |
|
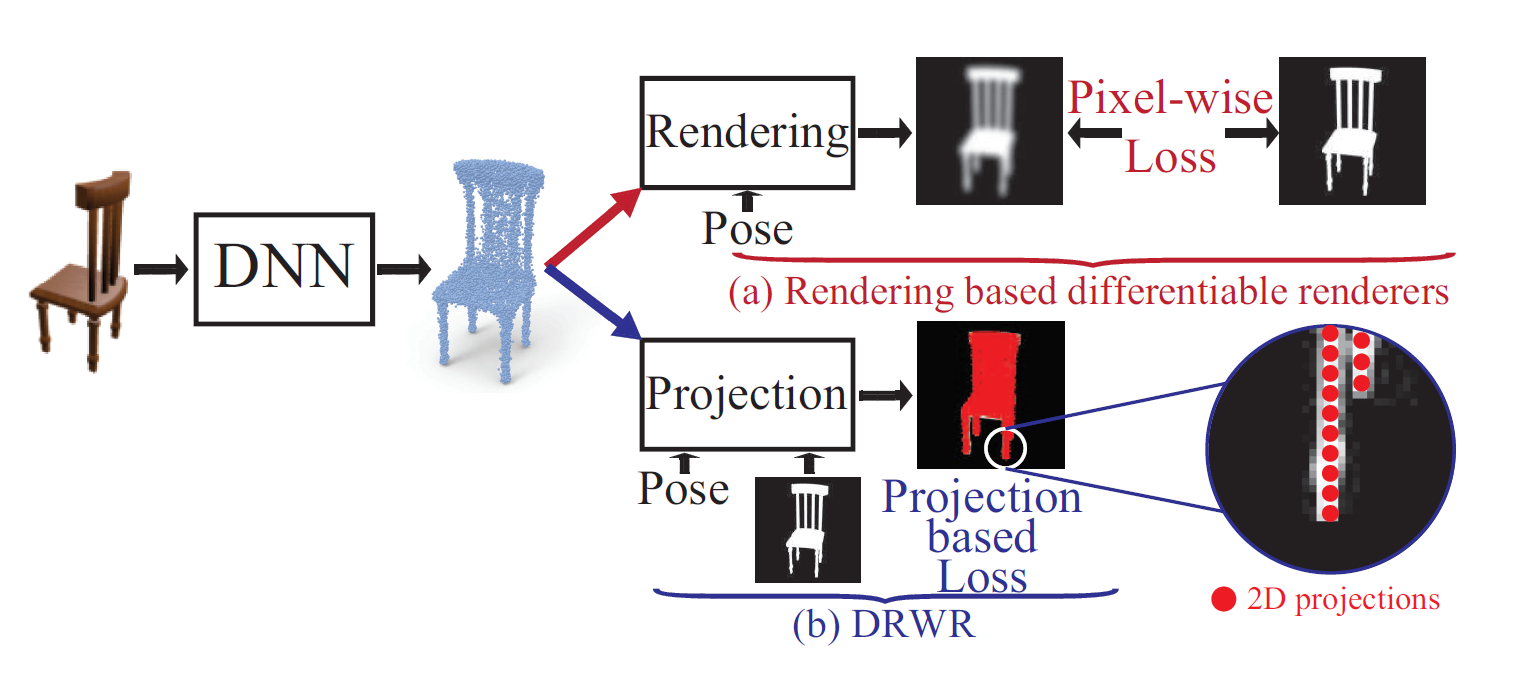
Zhizhong Han, Chao Chen, Yu-Shen Liu*, Matthias Zwicker, International Conference on Machine Learning (ICML), 2020 github / PMLR / arXiv We propose a Differentiable Renderer Without Rendering (DRWR) for unsupervised 3D point cloud reconstruction from 2D silhouette images. |
|
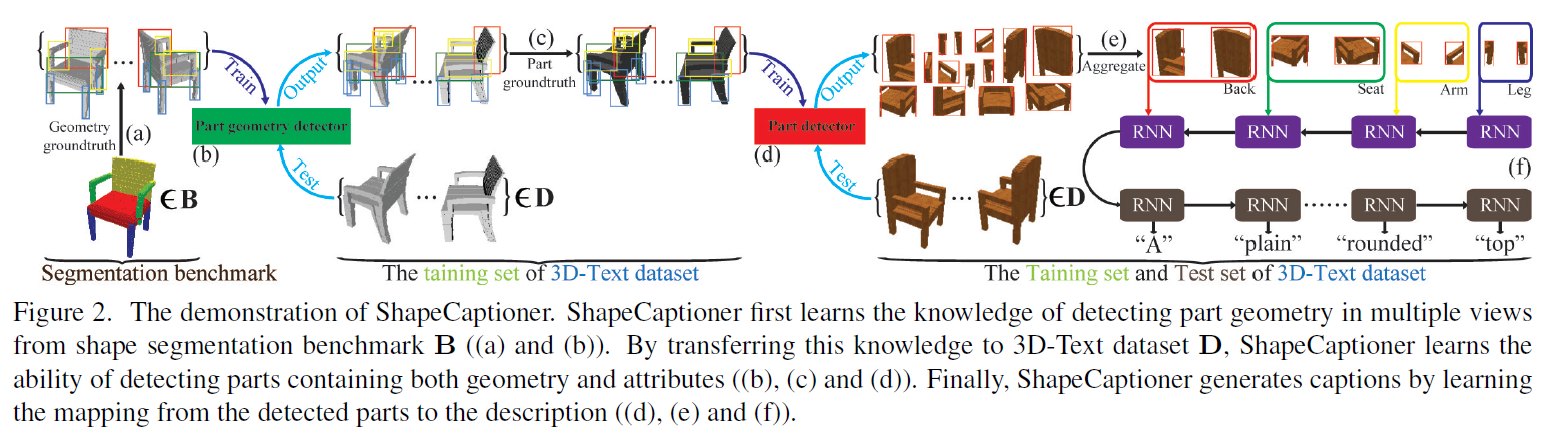
Zhizhong Han, Chao Chen, Yu-Shen Liu*, Matthias Zwicker, Proceedings of the 28th ACM International Conference on Multimedia (ACM MM), 2020 DOI / arXiv We propose ShapeCaptioner to enable 3D shape captioning from semantic parts detected in multi-views. |
|
Conference Reviewer: CVPR, ICCV, Siggraph Aisa, BMVC. |
|
Feel free to steal this website's source code. Do not scrape the HTML from this page itself, as it includes analytics tags that you do not want on your own website — use the github code instead. Also, consider using Leonid Keselman's Jekyll fork of this page. |